How to add quadratic constraint in conditional indicator constraints
AnsweredHi Gurobi Community,
I am trying to add a conditional indicator constraint using addGenConstrIndicator . E.g. a simple example like this:
import gurobipy as gp
m = gp.Model()
x = m.addVar(vtype=GRB.BINARY, name="x")
y = m.addVar(lb=-10, ub=10, name="y")
m.addGenConstrIndicator(x, True, y <= 4)
However, unfortunately in my case the constraint is not linear and it is quadratic but adding quadratic constraints like:
m.addGenConstrIndicator(x, True, y**2 <= 4)
seems to be not acceptable. I want to know is there another way or any sort of hack or workaround to this that I can add my quadratic constraint in the same way?
My real constraint is the following:
i = model.addVars(gurobi_variants, name='i', vtype=GRB.BINARY)
n = model.addVars(gurobi_replicas, name='n', vtype=GRB.INTEGER, lb=1, ub=scaling_cap)
b = model.addVars(gurobi_batches, name='b', vtype=GRB.INTEGER, lb=1, ub=batching_cap)
for stage in stages:
for variant in stages_variants[stage]:
model.addConstr((i[stage, variant] == 1) >> ((n[stage] * b[stage] - arrival_rate * func_l(b[stage], latency_parameters[stage][variant])) >= 0), f'throughput-{stage}')
all the other none Gurobi parameters like `stage` are constants in the above example. The terms:
n[stage] * b[stage]
is making it quadratic.
-

-
Gurobi Staff
Consider your simplified version of modeling \( x = 1 \implies y^2 \leq 4 \). Let \( \ell \) and \( u \) be \(y\)'s lower and upper bounds, respectively. We can model this implication with the constraint
$$\begin{align*}y^2 &\leq 4 + (M-4)(1-x),\end{align*}$$
where \( M = \max\{\ell^2, u^2\} \). In this case, \( M = 100 \).
If \( x = 1 \), then the constraint becomes \( y^2 \leq 4 \), as desired. If \( x = 0 \), then the constraint enforces \( y^2 \leq 100 \), which is redundant with \( y \)'s bounds.
0 -
-

Hi Eli,
Thank you for your answer! how about the situation where we have two distinct variables in our formulation that are making it quadratic e.g. $z.y <= 4$ then the only modification to your solution would be to change the $M$ to $M=max{l_{z} * l_{y}, u_{z} * u_{y}}$ and the formulation to $z.y <= 4 + (M-4)(1-x)$ where $l_{z}, l_{y}$ and ${u_z}$ and $u_y$ are the lower and upper bound of $z$ and $y$ respectively, correct?In a more complicated scenario I have ($x$ is the indicator variable):
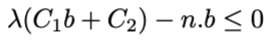
Where $n$ and $b$ are variables and the rest are constants. Can I do the same in the following format?
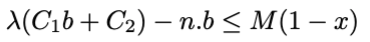
and set the $M$ to the following (considering all the variables and constants values are positive):
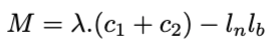
where $l_b$ and $l_n$ are lower bounds of variable $n$ and $b$, does such an extension from your solution make sense to you?
And is there any caveat to setting the value of $M$ to an extremely large number instead of explicitly computing $M$ with lower and upper bounds of variables? Will that have any effect on the performance of the optimizer?
Thanks!0 -
-
-
For the case of multiplying two distinct variables together, you should set
$$\begin{align} M &:= \max\{\ell_y \ell_z, \ell_y u_z, u_y \ell_z, u_y u_z\}.\end{align}$$
For example, for \( y \in [-2, -1] \) and \( z \in [1, 2] \), the maximum attainable value of \( yz \) is \( u_y \ell_z = -1 \).
In your more complicated scenario, it looks like you want to enforce
$$\begin{align} yz - \lambda (c_1 y + c_2) &\geq 0 \end{align}$$
when \( x = 1 \). Is that right? If so, we should derive a valid lower bound for \( y z - \lambda (c_1 y + c_2) \). We can break this into two parts:
- A lower bound for \( y z \) is \( m_1 := \min\{\ell_y \ell_z, \ell_y u_z, u_y \ell_z, u_y u_z\} \)
- A lower bound for \( - \lambda (c_1 y + c_2) \) is \( m_2 := - \max\{\lambda c_1 \ell_y, \lambda c_1 u_y \} - \lambda c_2 \).
Putting those two together, we have the constraint
$$\begin{align} y z - \lambda (c_1 y + c_2) &\geq (m_1 + m_2)(1 - x). \end{align}$$
You should not pick an arbitrary large value for \( M \). Not only can this cause numerical trouble for the model, but it often results in a weaker root relaxation, which can cause the model to take much longer to solve. A good rule of thumb is: your big-M values should be derived from the problem data.
0 -
-
Thanks Eli! It was very helpful!
0 -
Please sign in to leave a comment.
Comments
4 comments