Numpy matrix multiplication causes massive Ram usage + crash
AnsweredI have a gurobi model where I need to do a lot of matrix math operations. In Gurobi 8.1 I have been able to leverage numpy to give me the functions I required.
Loading vars into numpy like so
```
u = m.addVars(self.dims,1)
z = m.addVars(self.dims,1)
m.update()
u = np.array([[u[i,0]] for i in range(self.dims)])
z = np.array([[z[i,0]] for i in range(self.dims)])```
Then I do a lot of matrix multiplication with u and z. Using numpy arrays and np.dot(), these arrays are probably 1/2 made up of 0s. When I print my linExp I can clearly see several 0 terms included. For some scale models this has been fine but now that the model is larger and this model is multiplied by another matrix etc. The model explodes to contain an extreme amount of useless terms. My current model filled my 32GB of ram and crashed python nearly instantly.
Here is the simplest piece of code I was able to build that ran into my same issue.
https://gist.github.com/gftabor/58c8cd49849ab2615629bfbdb5174883
After 1 time being multiplied by identity matrix the expression is 10 times larger. And this behavior continues and crashes around 7 iterations in.
[[<gurobi.LinExpr: C0 + 0.0 C1 + 0.0 C2 + 0.0 C3 + 0.0 C4 + 0.0 C5 + 0.0 C6 + 0.0 C7 + 0.0 C8 + 0.0 C9>]
[<gurobi.LinExpr: 0.0 C0 + C1 + 0.0 C2 + 0.0 C3 + 0.0 C4 + 0.0 C5 + 0.0 C6 + 0.0 C7 + 0.0 C8 + 0.0 C9>]
[<gurobi.LinExpr: 0.0 C0 + 0.0 C1 + C2 + 0.0 C3 + 0.0 C4 + 0.0 C5 + 0.0 C6 + 0.0 C7 + 0.0 C8 + 0.0 C9>]
[<gurobi.LinExpr: 0.0 C0 + 0.0 C1 + 0.0 C2 + C3 + 0.0 C4 + 0.0 C5 + 0.0 C6 + 0.0 C7 + 0.0 C8 + 0.0 C9>]
[<gurobi.LinExpr: 0.0 C0 + 0.0 C1 + 0.0 C2 + 0.0 C3 + C4 + 0.0 C5 + 0.0 C6 + 0.0 C7 + 0.0 C8 + 0.0 C9>]
[<gurobi.LinExpr: 0.0 C0 + 0.0 C1 + 0.0 C2 + 0.0 C3 + 0.0 C4 + C5 + 0.0 C6 + 0.0 C7 + 0.0 C8 + 0.0 C9>]
[<gurobi.LinExpr: 0.0 C0 + 0.0 C1 + 0.0 C2 + 0.0 C3 + 0.0 C4 + 0.0 C5 + C6 + 0.0 C7 + 0.0 C8 + 0.0 C9>]
[<gurobi.LinExpr: 0.0 C0 + 0.0 C1 + 0.0 C2 + 0.0 C3 + 0.0 C4 + 0.0 C5 + 0.0 C6 + C7 + 0.0 C8 + 0.0 C9>]
[<gurobi.LinExpr: 0.0 C0 + 0.0 C1 + 0.0 C2 + 0.0 C3 + 0.0 C4 + 0.0 C5 + 0.0 C6 + 0.0 C7 + C8 + 0.0 C9>]
[<gurobi.LinExpr: 0.0 C0 + 0.0 C1 + 0.0 C2 + 0.0 C3 + 0.0 C4 + 0.0 C5 + 0.0 C6 + 0.0 C7 + 0.0 C8 + C9>]]
So while demo is pretty made up test, my actual model ends up looking like this https://pastebin.com/euSJtCz1 right before crashing.
So is there a clean way to simplify an expression to remove "bloat". Or another way to leverage numpy arrays with gurobi objects, it seems like gurobi should return 0 from 0.0*C5 instead of keeping it around. 1 idea I had before was to right my own copy of all matrix operations and not include terms that had 0 in them but that doesn't scale well as I need more operations.
-
Official comment

-
Gurobi Staff
This post is more than three years old. Some information may not be up to date. For current information, please check the Gurobi Documentation or Knowledge Base. If you need more help, please create a new post in the community forum. Or why not try our AI Gurobot?. -
-

My current short term solution is to call this prune function occasionally but its pretty sloppy. Each array will go up and down in ram usage by 10x every function call. Also it is clearly pretty shape specific, but that would be solvable if I wanted.
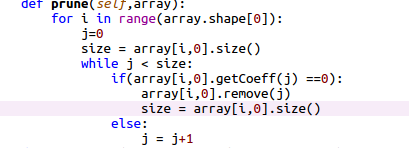
The other solution is to break my model into hundreds of intermediate steps. With each intermediate step having a constraint to equal the variable used in the next step. Best case though this stops the 10^50 factor of ram waste and caps it at likely a factor of only 10. (numbers being how much ram is wasted per useful piece of ram)
0 -
-

-
Hello Griffin,
the bloat you are observing comes from the exponentially growing size of the symbolic representations of the linear expressions. Looking at your the example code (modified for brevity):
import gurobipy as gp
import numpy as np
import time
dims = 10
m = gp.Model("mip")
u = np.array(m.addVars(dims).values())
m.update()
matrix = np.eye(dims)
for i in range(7):
start = time.time()
u = np.dot(matrix, u)
nterms = sum(expr.size() for expr in u)
print("Iteration {:2d}, time={:5.2f}sec, nterms={:10d}".format(
i, time.time() - start, nterms))On my machine this gives the following output:
Iteration 0, time= 0.00sec, nterms= 100
Iteration 1, time= 0.00sec, nterms= 1000
Iteration 2, time= 0.00sec, nterms= 10000
Iteration 3, time= 0.01sec, nterms= 100000
Iteration 4, time= 0.15sec, nterms= 1000000
Iteration 5, time= 1.53sec, nterms= 10000000
Iteration 6, time=26.03sec, nterms= 100000000At each iteration u is an ndarray of (ten) LinExpr objects, but the multiplication with 'matrix' increases the representation size of each such linear expression by a factor of ten, leading eventually to an exponentially growing run time. (Obviously the LinExpr class could be implemented smarter to collect terms, remove zero coefficients, etc. -- maybe in the future).
This can easily be avoided if you change the order of evaluation from, say, A*(A*(A*x)) to ((A*A)*A)*x, so that all multiplications except for the last one is among ndarrays. For the above example, this could be done as follows:
import gurobipy as gp
import numpy as np
import time
dims = 10
m = gp.Model("mip")
u = np.array(m.addVars(dims).values())
m.update()
matrix = np.eye(dims)
# Compute product of matrices
for i in range(7):
start = time.time()
matrix = np.dot(matrix, matrix)
print("Iteration {:2d}, time={:5.2f}sec".format(
i, time.time() - start))
# Now multiply the product with the variables
start = time.time()
u = np.dot(matrix, u)
nterms = sum(expr.size() for expr in u)
print("Final result: time={:5.2f}sec, nterms={:10d}".format(
time.time() - start, nterms))which gives on my machine
Iteration 0, time= 0.00sec
Iteration 1, time= 0.00sec
Iteration 2, time= 0.00sec
Iteration 3, time= 0.00sec
Iteration 4, time= 0.00sec
Iteration 5, time= 0.00sec
Iteration 6, time= 0.00sec
Final result: time= 0.00sec, nterms= 100Hope that helps!
Robert
1 -
-
We are totally on the same page on what is going on. Thank you for explaining it so much more succinctly than I did. The example case A*A*A*A*A*A*A*x is pretty contrived and is easily solved by precomputing the non symbolic components. I am a less confident in the ability to do that on my real model, at least in all cases.
I have been reorganizing my model such that I no longer have the exponential explosion. My task is a motion planner with lots of integer components. In my original formulation I was trying to minimize X at time step 50. Where for each timestep I declare a set of gurobi decision variables and pass the state and the decision through a simulator. Thus X at time step 50 had been passed through the simulator 50 times. In my new formulation I just say minimize X(50) with constraints for X(t+1) = simulator(X(t),decision). This should be an equivalent formulation however it means a single expression only ever passes through my simulator once. I am now able to actually run the optimization instead of crashing trying to formulate it.
I would however like to request this update being added to the roadmap (Obviously the LinExpr class could be implemented smarter to collect terms, remove zero coefficients, etc. -- maybe in the future). We can still see from your example
Iteration 0, time= 0.00sec, nterms= 100
that 10 terms turned into 100 even when we precompute to the best of our ability. I would hope the Presolve step does this simplification somewhere? Or there is some other reason to expect these added terms don't also increase the optimization time?
Lastly I just would like to justify why I think this numpy approach is advantageous. I have existing functions designed without symbolic math in mind. For example a simulator that I use when evaluating the decision variables provided by my optimization. By loading them into numpy arrays I am able to pass the numpy arrays into the same function and instead of getting a float output, I get a symbolic one. If I switched to using special gurobi functions for handling matrix operations I would need to maintain 2 copies of the same function with all the obvious downsides that provides. I will need to look into the gurobi 9 matrix API to see if I can get the same benefit. (PS, thanks for modifying code for brevity, you clearly know more about your API than I do)
0 -
-
-
Hello Griffin,
I have created a feature request to deal with term collection and dropping zero terms in LinExpr objects. For sure such zero terms are disposed of some time before the actual optimization starts, but not while LinExpr objects are created.
For now you could work around this by explicitly simplifying the exploding LinExpr objects after each multiplication youself. Here is an example how to do that. Note that this technique is not very efficient, but if the goal is only to avoid exponential run time, even slow code shines.
import gurobipy as gp
import numpy as np
import time
from collections import defaultdict
def simplify_linexpr(le):
# Collect terms and drop zeros in the given gp.LinExpr object.
coeflist = [le.getCoeff(i) for i in range(le.size())]
varlist = [le.getVar(i) for i in range(le.size())]
constant = le.getConstant()
le.clear() # Remove all terms, and constant
# Rebuild le without zeros and collected terms
le.addConstant(constant)
merged_pairs = defaultdict(lambda: 0.0)
for (coef, var) in zip(coeflist, varlist):
if coef != 0.0:
merged_pairs[var] += coef
le.addTerms(merged_pairs.values(), merged_pairs.keys())
dims = 10
m = gp.Model("mip")
u = np.array(m.addVars(dims).values())
m.update()
matrix = np.eye(dims)
for i in range(7):
start = time.time()
u = np.dot(matrix, u)
for expr in u:
simplify_linexpr(expr)
nterms = sum(expr.size() for expr in u)
print("Iteration {:2d}, time={:5.2f}sec, nterms={:10d}".format(
i, time.time() - start, nterms))On my machine I now see
Iteration 0, time= 0.00sec, nterms= 10
Iteration 1, time= 0.00sec, nterms= 10
Iteration 2, time= 0.00sec, nterms= 10
Iteration 3, time= 0.00sec, nterms= 10
Iteration 4, time= 0.00sec, nterms= 10
Iteration 5, time= 0.00sec, nterms= 10
Iteration 6, time= 0.00sec, nterms= 10I understand that this will be cumbersome to integrate if you want to maintain a single code path that eats both ndarrays of Var objects, and normal ndarrays, but this is as close as you can get by simple means.
Robert
0 -
Post is closed for comments.
Comments
5 comments