Gurobi takes very long time to solve MIQP
回答済みMy problem is to minimize the first formular subject to the second inequality using MIQP. Now it takes very long time for around 100 data points. Is there any ways to improve the speed? Appreciate your suggestions!

-
正式なコメント

-
Gurobi Staff
This post is more than three years old. Some information may not be up to date. For current information, please check the Gurobi Documentation or Knowledge Base. If you need more help, please create a new post in the community forum. Or why not try our AI Gurobot?. -
-

-
Hi,
Could you elaborate more on your problem? In particular, what are the variables, scalars, and \(s\)? How are you currently modeling the term \(1\{ f_t - f_{t-1} \neq f_{t+1} - f_t \}\) and what exactly do you mean by this term? Did you try solving the problem with less data points, e.g., 10? You can also provide access to your model as described in Posting to the Community Forum.
Best regards,
Jaromił0 -
-

Hi Jaromil, thanks very much for your reply. I write my problem details in below. Looking forward to your kind advice.
yt, t=1,…T are observations.
Let y denote the (T × 1) vector of yt ’s and 1 a vector of 1’s whose dimension may vary.
We want to solve
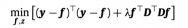
subject to
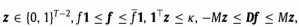
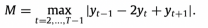
λ and κ are two tuning parameters.
D is the (T − 2) × T second-order difference with entries not shown above being zero.
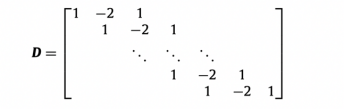
Then we can get f_hat (the trend estimate of yt) and also z_hat . Then we can calculate

The tunning parameter κ ∈{2,3,4} and the possible value for λ is {1,2,4,8,16,32}.We want to use leave 1 out cross validation to select the tuning parameter λ and κ. But in the experiment, it seems that when the observations number is less than 100, the algorithm takes 15 to 20 minutes to get the optimal. But when the observations number is bigger than 180, the algorithm will run for a very long time in R and cannot get the results.
0 -
-
-
How are you modeling the \(\max\) function? Are you using the addGenConstrMax function or are you modeling it yourself?
Could you also share 2 problem instances? One solving within ~15 minutes and one taking way longer? This would make investigation and the process of coming up with a recommendation way easier.
0 -
-
We don’t need to model the max function. M can be actually calculated when we get the observations y1…yT by the formula
For example, we got observations yt (t=1…97),
[1] -1.2104033 -0.8765552 -1.0286865 -0.8155427 -1.0042889 -1.0991677
[7] -0.9891735 -0.9515760 -0.8166840 -1.1236295 -1.2206734 -1.2253039
[13] -1.2169080 -1.0781534 -1.1703728 -0.7627710 -0.7467879 -0.6637389
[19] -1.0424596 -1.1292267 -1.2407069 -1.3382986 -1.3972085 -1.4134551
[25] -1.4498958 -1.6339248 -1.7517438 -1.8105171 -1.8466570 -1.8559857
[31] -1.9240445 -1.9595071 -2.0992153 -2.2262495 -2.3470260 -2.3830781
[37] -2.4068163 -2.4533036 -2.5367031 -2.6674077 -2.8189016 -2.9006591
[43] -2.9364815 -2.9009759 -2.8866849 -2.8920875 -2.9865647 -3.0944776
[49] -3.1975780 -3.2020985 -3.1997418 -3.1330625 -3.1157847 -3.1543598
[55] -3.3347060 -3.4725674 -3.5013753 -3.4315843 -3.3311393 -3.3249703
[61] -3.3799530 -3.5437414 -3.6320468 -3.6595430 -3.6072013 -3.5907503
[67] -3.6035211 -3.7249569 -3.8624705 -3.9392416 -3.9298745 -3.8060444
[73] -3.7719537 -3.7329444 -3.8626897 -3.9271165 -4.0117101 -3.9533291
[79] -3.9093787 -3.8726056 -3.8974279 -3.9657570 -4.0376118 -4.0974700
[85] -4.1484192 -4.0959559 -4.0150577 -3.9387246 -3.9861372 -4.0434174
[91] -4.0993742 -4.1073161 -4.1090623 -4.0563510 -4.0205101 -3.9964019
[97] -4.1187929
M can be calculated directly in R by max(abs(diff(x = yt, differences = 2))) and equal to 0.49. So M can be regarded as a constant in the model
The problem solving within 15 minutes is that we use the observations yt (t=1…97) above to do the cross-validation. There are 18 different combinations of (λ, κ) as stated before.
var1 var2
1 1 2
2 2 2
3 4 2
4 8 2
5 16 2
6 32 2
7 1 3
8 2 3
9 4 3
10 8 3
11 16 3
12 32 3
13 1 4
14 2 4
15 4 4
16 8 4
17 16 4
18 32 4
For each combination of λ and κ,
let y1=0, fit the model using result<-gurobi (model,param) and get a number result$x[1]
……
Let y97=0, fit the model using result<-gurobi (model,param) and get a number result$x[97].
Combine these 97 different numbers into a vector betaHat_s.
Calculate the objective value t(betaHat_s - yt) %*% (betaHat_s - yt).
For each combination of λ and κ, repeat these procedures then we can get 18 objective values.
The whole process takes about 15 minutes in total.
The one taking way longer is just increase the sample size of yt, now we have yt (t=1…370) which is much bigger than the one before (97).
0 -
-
-
Thank you for the clarification. It is expected that the solution time increases because with the increased sample size, you also introduce more variables and more quadratic terms.
What you might want to try is to use the Gurobi parameter tuning tool on the easier instances to possibly derive good parameters and speed up the overall optimization process for the harder instances.
Do you have any additional knowledge on the problem which you might use in order to reduce the number of quadratic terms?
0 -
-
Jaromil,
Thanks for the advice. I do not think I know enough on reduction of the number of quadratic term. I tried to figure out and not yet achieved. I watched a gurobi tutorial that mentioned about quadratic term performance improvement but it was very short. There could be other tutorials that talk more about it. Would you happen to know any?
Regards
Liu Na
0 -
-
-
Hi Liu Na,
In addition to our webinar on Non-Convex Quadratic Optimization, there is also the webinar on Models with Products of Binary Variables. In addition to experimenting with Gurobi's parameter tuning tool, you might also want to have a look at the list of Most important parameters. Your problem should fall into the category of parameter estimation, thus you could search for specific algorithms and reformulations in the literature.
Best regards,
Jaromił0 -
投稿コメントは受け付けていません。
コメント
8件のコメント