About constants affect optimization results
回答済みHi,
I'm solving a simple optimization problem, the specific form can be expressed as
MAX ∑∑ (-1 * norm(q[j] - s[k]) ** 2).
Obviously, this is a convex optimization problem.
About my question.
- Why do two pieces of code produce different results? I don't think the difference between the two codes should cause different output results. The dc part does not involve decision variables, which is my reason. I also consider whether (dc * * 4) causes the numerical accuracy problem, but the value of qc is very small, even to the fourth power, it will not be very large, so I don't think it is an accuracy problem.
term2[k, j] = -1 * (l[k, j] * l[k, j])term2[k, j] = -1 * (l[k, j] * l[k, j]) / (dc[k, j]** 4)
#dc[k, j] = np.norm(qc[j] - s[k]) qc and s have been given
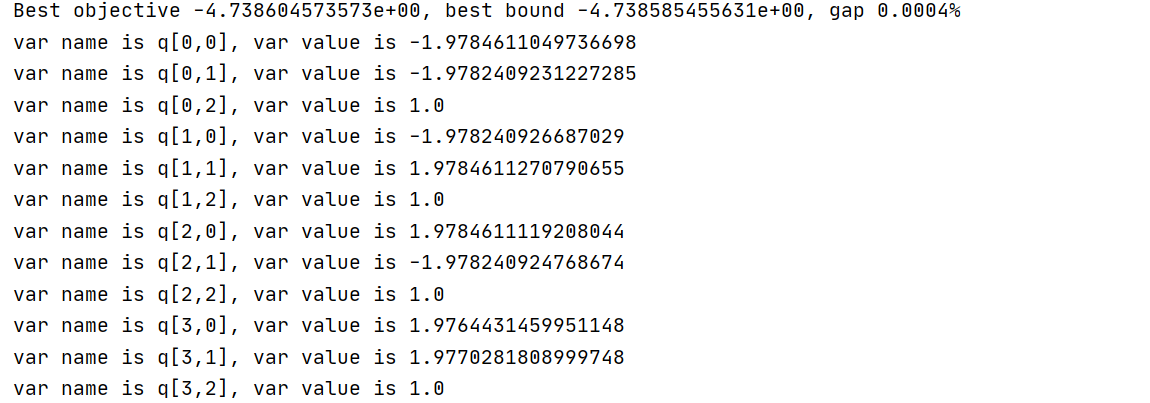
- Here is my code and running results
def gurobi_help():
model = grb.Model('')
s = np.array([[-2, -2, 0], [-2, 2, 0], [2, -2, 0], [2, 2, 0]])
qc = [[-2, -2, 1], [-2, 2, 1], [2, -2, 1], [2, 2, 1]]
q = model.addVars(4, 3, lb=-5, vtype=GRB.CONTINUOUS, name='q')
term2 = model.addVars(4, 4, vtype=GRB.CONTINUOUS, name='term2')
l = model.addVars(4, 4, vtype=GRB.CONTINUOUS, name='l')
dc = np.array([[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]])
for k in range(K):
for j in range(K):
dc[k, j] = np.linalg.norm(qc[j] - s[k])
print(dc[k, j])
model.update()
sum = LinExpr()
for k in range(K):
for j in range(K):
#-------------------------------------------------------------------------------
term2[k, j] = -1 * (l[k, j] * l[k, j])
#-------------------------------------------------------------------------------
sum += term2[k, j]
model.setObjective(sum, sense=GRB.MAXIMIZE)
for k in range(4):
model.addConstr(q[k, 2] == 1)
model.addConstr(q[k, 0] <= 5)
model.addConstr(q[k, 0] >= -5)
model.addConstr(q[k, 1] <= 5)
model.addConstr(q[k, 1] >= -5)
# np.linalg.norm(q[j] - s[k])
for k in range(4):
for j in range(4):
rhs = QuadExpr()
for i in range(3):
rhs += q[j, i] * q[j, i] - 2 * s[k][i] * q[j, i]
model.addConstr(l[k, j] * l[k, j] == rhs + s[k][0] ** 2 + s[k][1] ** 2 + s[k][2] ** 2)
model.setParam('NonConvex', 2)
model.setParam('NumericFocus', 3)
model.optimize()
for v in model.getVars():
print('var name is {}, var value is {}'.format(v.VarName, v.X))

def gurobi_help():
model = grb.Model('')
s = np.array([[-2, -2, 0], [-2, 2, 0], [2, -2, 0], [2, 2, 0]])
qc = [[-2, -2, 1], [-2, 2, 1], [2, -2, 1], [2, 2, 1]]
q = model.addVars(4, 3, lb=-5, vtype=GRB.CONTINUOUS, name='q')
term2 = model.addVars(4, 4, vtype=GRB.CONTINUOUS, name='term2')
l = model.addVars(4, 4, vtype=GRB.CONTINUOUS, name='l')
dc = np.array([[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]])
for k in range(K):
for j in range(K):
dc[k, j] = np.linalg.norm(qc[j] - s[k])
print(dc[k, j])
model.update()
sum = LinExpr()
for k in range(K):
for j in range(K):
#-------------------------------------------------------------------------------
term2[k, j] = -1 * (l[k, j] * l[k, j]) / (dc[k, j]** 4)
#-------------------------------------------------------------------------------
sum += term2[k, j]
model.setObjective(sum, sense=GRB.MAXIMIZE)
for k in range(4):
model.addConstr(q[k, 2] == 1)
model.addConstr(q[k, 0] <= 5)
model.addConstr(q[k, 0] >= -5)
model.addConstr(q[k, 1] <= 5)
model.addConstr(q[k, 1] >= -5)
# np.linalg.norm(q[j] - s[k])
for k in range(4):
for j in range(4):
rhs = QuadExpr()
for i in range(3):
rhs += q[j, i] * q[j, i] - 2 * s[k][i] * q[j, i]
model.addConstr(l[k, j] * l[k, j] == rhs + s[k][0] ** 2 + s[k][1] ** 2 + s[k][2] ** 2)
model.setParam('NonConvex', 2)
model.setParam('NumericFocus', 3)
model.optimize()
for v in model.getVars():
print('var name is {}, var value is {}'.format(v.VarName, v.X))
return [[q[i, j].X for j in range(3)] for i in range(4)]
-
正式なコメント

-
Gurobi Staff
This post is more than three years old. Some information may not be up to date. For current information, please check the Gurobi Documentation or Knowledge Base. If you need more help, please create a new post in the community forum. Or why not try our AI Gurobot?. -
-

-
If you divide every objective term by the same constant, the optimal solution(s) would not change. However, you are dividing each objective term by different constants. In the first example, the objective function is the sum of squares:
\begin{align*}\max\ -\ell_{00}^2 - \ell_{01}^2 - \ldots - \ell_{32}^2 - \ell_{33}^2.\end{align*}
In the second example, the quadratic objective terms now have coefficients \( 1 \), \( \frac{1}{256} \), or \( \frac{1}{625} \), because the corresponding \( \texttt{dc} \) values vary:
\begin{align*}\max\ -\ell_{00}^2 - \frac{1}{256}\ell_{01}^2 - \ldots - \frac{1}{256} \ell_{32}^2 - \ell_{33}^2.\end{align*}
Scaling the objective terms differently can result in a different optimal solution. As a simple example, consider the following problem:
\begin{align*}\max_{x,y}\ x + y \\ \textrm{s.t.}\ x + 4y &\leq 4 \\ y &\leq 1 \\ x, y &\geq 0.\end{align*}
The optimal solution is \( (x^*, y^*) = (4, 0) \). However, if we change the objective function to \( \frac{1}{10}x + y \), the optimal solution changes to \( (x^*, y^*) = (0, 1) \).
0 -
-

Hi Eli Towle,
First of all, I'm sorry for the trouble I brought you. I've been looking for the reason why the problem went wrong, but I ignored the problem itself. Thank you very much for your answer. Your example makes me easily recognize my mistake.
Best regards,
Yanbo
0 -
投稿コメントは受け付けていません。
コメント
3件のコメント